A stream is a data sequence that has no bound, no ending and keeps flowing continuously. Each record in a stream comprises of key and value. The Kafka Streams API manifests itself as a way to transform and enrich (consume and produce) this data flow in record level (no micro-batching) with a very low latency (in milliseconds) via taking the processing effort out of Kafka cluster. The API brings methods for stateless processing such as filter and map with methods for stateful processing such as join and aggregate as well. There are also out-of-box support for windowing operations with analyzing set of records in a definite time frame/boundary.
One of the most charming capabilities of Kafka Streams API is a real-time stream processing application can be implemented as a cross-platform, easy-to-deploy microservice using standard Java language without need of a disparate processing cluster. It leads to having an elastic, scalable and fault-tolerant event stream processing stack in application layer. Being backed by a state-of-art distributed system like Kafka with embracing Microservices Architecture (MSA) lends itself to the main tenet of a stream processing application. The computation of streaming needs to be done on a multi node system for the sake of performance and parallelization (partition, replication, grouping, etc.). To sum up Kafka Streams provides a stream processing API that has:
- Local (on an embedded key-value store) and fault-tolerant state management
- Rich set of operators for transforming streams of data via enrichment, transformation and processing
- Advanced representations of streams such as aggregations and tables
- Sophisticated handling of time such as windowing
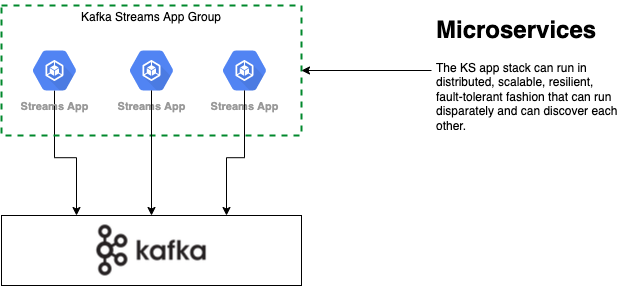
Kafka Streams as a Data Processing System
A data processing system should cover three main non-functional requirements:
- Scalability
- Reliability
- Maintainability
Scalability
A data processing system should perform well under load. The unit of work in Kafka Streams app is the topic partition that it subscribed to. The topics can be expanded by adding more partitions. Increasing number of partitions on source topics enable to distribute load across these partitions and across the apps that consume from them. Kafka Streams API also supports consumer groups. An event processing computation on topic can be distributed across multiple, cooperating instances of app in a group.
Reliability
A data processing system should behave consistent in case of error with no crash in any noticeable way (no outage) and with no data loss or corruption. If any of Kafka Streams app in a group crashes, Kafka automatically re-distributes the load to other healthy instances. The consumer group also makes parallel processing and load balancing possible for a topic.
Maintainability
On-going maintenance, bug fixing, debugging and keeping system operational should be straightforward for a data processing system. Kafka Streams API is a Java based library that has huge community, myriad of best practices, and debugging, monitoring and analyzing easiness. Well known data processing systems like Apache Spark and Apache Flink need a dedicated processing cluster for submitting and running stream processing tasks. They also use micro-batching to achieve greater throughput that turns to be latency in processing completion. On the contrary, Kafka Streams apps externalize processing from Kafka cluster and maintains high throughput with low latency by parallelizing processing via splitting data across many partitions for a topic.
Relations or tables are first-class citizens in Kafka Streams API, where each has an independent identity. Relations can be transformed into other relations:
// Compute the number of clicks per region, e.g. "europe".
//
// The resulting KTable is continuously being updated as new data records are arriving in the
// input KStream `userClicksStream` and input KTable `userRegionsTable`.
final KTable<String, Long> clicksPerRegion = userClicksStream
// Join the stream against the table.
//
// Null values possible: In general, null values are possible for region (i.e. the value of
// the KTable we are joining against) so we must guard against that (here: by setting the
// fallback region "UNKNOWN"). In this specific example this is not really needed because
// we know, based on the test setup, that all users have appropriate region entries at the
// time we perform the join.
//
// Also, we need to return a tuple of (region, clicks) for each user. But because Java does
// not support tuples out-of-the-box, we must use a custom class `RegionWithClicks` to
// achieve the same effect.
.leftJoin(userRegionsTable, (clicks, region) -> new RegionWithClicks(region == null ? "UNKNOWN" : region, clicks))
// Change the stream from <user> -> <region, clicks> to <region> -> <clicks>
.map((user, regionWithClicks) -> new KeyValue<>(regionWithClicks.getRegion(), regionWithClicks.getClicks()))
// Compute the total per region by summing the individual click counts per region.
.groupByKey(Grouped.with(stringSerde, longSerde))
.reduce(Long::sum);
Processor Topology in Kafka Streams API
Each Kafka Stream application is designed to perform computation on real-time event stream. The combination of computational logic (map, filter, join, aggregation) coded inside the KS app shapes a processor topology. Each computational logic/processing step is a stream processor connected via streams or shared state stores. Different types of stream processors exists:
- Source Processor: This type of processor has no upstream processor and just reads data from a topic to send to one or more downstream processors.
- Sink Processor: This type of processor just sends received records from up-stream processors to a Kafka topic. It just writes resultant records of computations performed by upstream processors back to Kafka and has no downstream processors.
A topology processes records one by one, until a record visits each stream processor. After all processing is done for a record next one is processed. If a topology comprises of sub-topologies aforementioned strategy is just applied in sub-topology level not for main topology.
Parallelism of Processing
Kafka Streams apps benefit from Kafka’s capability of partitioning to parallelize event processing. Kafka Streams API has the ability to create a stream task per input topic partition that is the smallest unit of work. So, maximum number of parallel running tasks equals to number of partitions in input topic. If a topology reads from a topic with 5 partitions:
- KS app creates 5 tasks.
- Each task instantiates its own copy of underlying processor topology.
- These tasks assigned to source topic’s partitions.
It is also possible to configure number of threads that Kafka Streams library can use for process parallelization. There exists one to many relation between threads and tasks, as each thread can execute single or multiple tasks at a time. Each thread is isolated, and thread safe so that each processor runs its own topology independently and in parallel. It is possible to specify thread count using num.stream.threads configuration and the maximum number of threads equals number of tasks.
Streams and Tables
A stream in Kafka Streams context resembles an insert operation on a database table. Each distinct record is appended to the actual view of Kafka log (as in a Blockchain ledger).

A table in Kafka Streams world resembles an update operation on a database table. Only latest or aggregated state/value is retained for an event key. Tables are materialized on KS app using a key-value state store based on RocksDB. IOW, KS app hosts a local copy of actual state of events per key from table abstractions. In Kafka Streams context, table is not something consumed from Kafka, but something built on application side.

To achieve true resiliency, any data stored in a local state store is also stored remotely on Kafka changelog topics. Changelog topic is compacted topic which only keeps the latest value of an event for a key. In case any KS app failure or restart, a table’s data can always be restored from its change stream via changelog topic by same application or another application in a group. It is also possible to persist state store on disk asynchronously (state.dir configuration). In normal conditions, KS app keeps smaller data in memory until it gets bigger or write buffer is full. Otherwise, it spills state to persistent file system. So that, state can be re-built using this data on dik instead of replaying entire topic and only missing data on local state is replayed from topic.
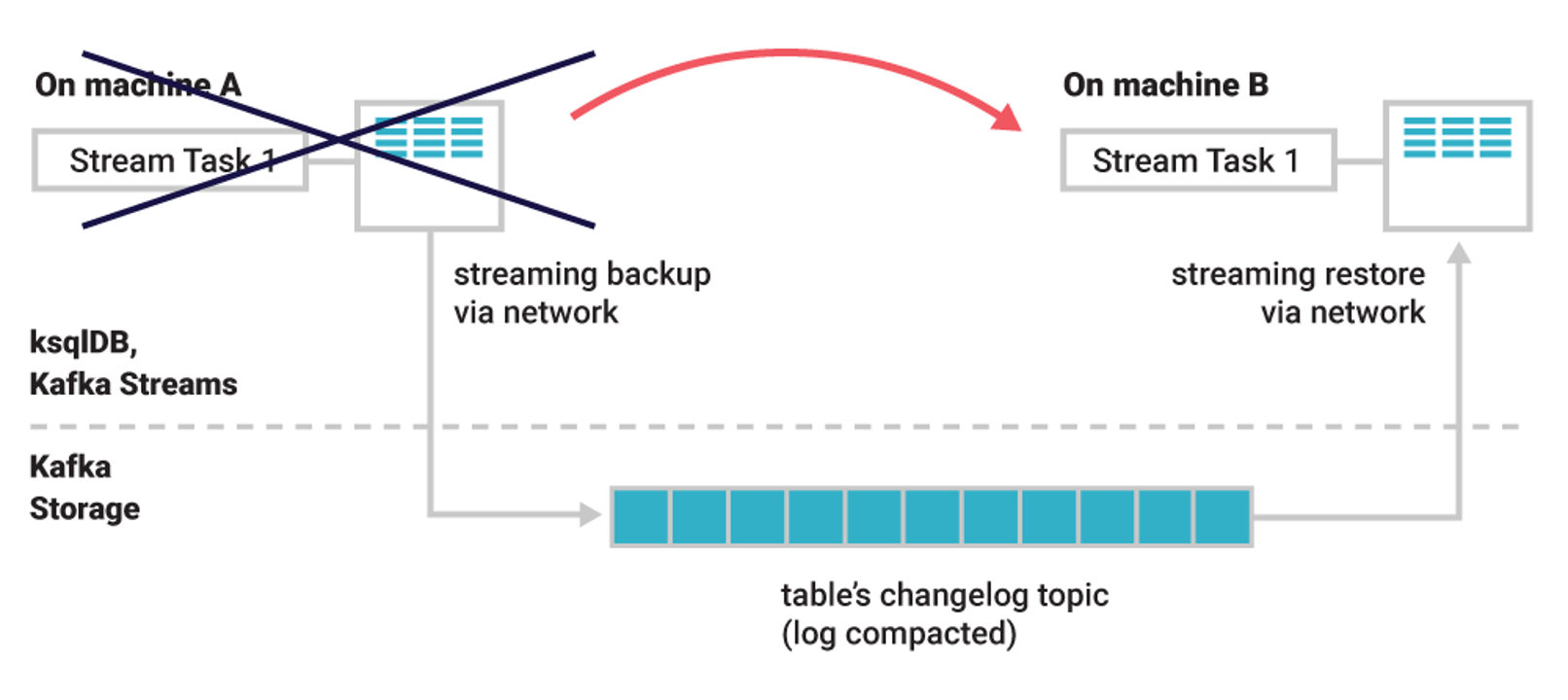
With Kafka Streams, it is possible to specify the amount of memory used for a topology instance. The internal cache maintained on KS app uses that memory to compact records before they are persisted on state stores, or forwarded downstream processors. This memory is shared evenly across Kafka Stream threads in a topology where each thread manages a memory pool available for tasks in a processor nodes. In essence, this is used by processors (nodes) that perform stateful operations like aggregation backing with a local state store.
Kafka Streams API has a high-level DSL (Domain Specific Language) that enables to use capabilities/processing formats above via some abstractions. These abstractions are:
KStream
KStream is an abstraction of a record stream on a source topic partition. Data is represented as independent events based on insert semantics (Sample Code).
KTable
It is an abstraction of a partitioned table (changelog stream). Data is represented using update semantics. KTables are partitioned. Each KS task only contains a subset of full table (topic partition). It is a real-time snapshot of fast-moving event stream and can be queried instantly. It is also possible to build relations on a bunch of streams using KTable. With the combination of low-latency, event-driven, microservices architecture compliant nature of KS apps, KTable is a well-suited API for stream relational processing. For large key spaces (lots of uniqueness), KTable is able to distribute fragments of entire state across KS app instances. As fragmentation is in effect, this API brings less storage overhead on KS apps (Sample Code).
GlobalKTable
GlobalKTable resembles KTable except it contains complete (un-partitioned) copy of underlying data in each KS app that it is used
(Sample Code).
Co-partitioning
KStream-KStream, KTable-KTable, KStream-KTable joins require co-partitioning. To achieve true relation between events or compute aggregations on sequence of events related events should be routed to same partition and they should be handled by same task. KStream-GlobalKTable joins does not require co-partitioning as state is fully replicated/un-partitioned in GlobalKTable. There exists some requirements for co-partitioning:
- Records on both sides must be keyed by same field.
- Records on both sides must be partitioned on that key as same partitioning strategy should be used for that key (re-keying).
selectKeymethod is used on un-keyed KStream. Re-keying ensures related records appear on same partition (Sample Code):
Grouping
Stream or table data needs to be re-grouped before aggregation. The aim is to ensure that related records are processed by same task. Following operators are used for grouping streams:
groupBy: It is similar withselectKeyand used re-partitioning of topic. For tables this method is required only.groupByKey: It is used when re-keying is not required where records are already keyed with desired scheme. It is more performant.
Windows
To unleash full power of Kafka Streams API, the relation between events and time should be understood. Windows allow to group events into explicit time buckets and they can be used for more advanced joins and aggregations. Before proceeding with windowing the definition of time in Kafka Streams context should be understood. There exists three type of time in Kafka Streams:
Event Time
It is the time when an event is generated at the source. It can be embedded in event payload or it can be set directly using producer.
Ingestion Time
It is the time when an event is appended to a partition on a broker node. It always occurs after event time.
Processing Time
It is the time when the event is processed by KS app. It occurs after event and ingestion times. It is less static that event time which means re-processing same data will lead to new processing timestamps. So, it may lead to non-deterministic windowing behavior as the processing time changes again and again based on WallClockTimeStampExtractor.
Configuration
- Parameters:
log.message.timestamp.type- Broker Levelmessage.timestamp.type- Topic Level
- Valid Values:
CreateTime- When using event timeLogAppendTime- When using ingestion time
Windowing
Windowing is a method for grouping records into different time-based subgroups for aggregating and joining. It lets to group records that have same key for stateful operations (e.g. aggregations, joins) into time spans. There are several types of windowing methods:
- Tumbling Windows:
- Windows are in fixed size that never overlap.
- Is defined using “window size” (in milliseconds)
- Have predictable time ranges since they are aligned with the epoch and each other
- 1st window starts at timestamp 0: 0-5, 5-10, 10-15
- Start time is inclusive, end time is exclusive
- Hopping Windows:
- Windows are in fixed size that may overlap.
- 2 parameters needed: Window size, advance interval (how much window moves forward)
- Session Windows:
- Variable-sized windows determined by periods of activity followed by gaps of inactivity
- Defined using “inactivity gap”:
- If it is 5 seconds each record that has a timestamp within 5 secs of the previous record with the same key will be merged into same window.
- Both the lower and upper boundaries are inclusive.
- Useful for user behavior analysis (e.g. Counting user visits on a digital channel, customer-conversion rate)
- Sliding Join Windows:
- Fixed size windows used for joining and has only defined via “window size” parameter
- 2 records fall within the same window when “time difference between them” ≤ “window size”
- Lower and upper bounds are inclusive. Keys must match since streams are joined.
- Sliding Aggregation Windows:
- Sliding Windows with “time difference” and “grace” (
SlidingWindows.withTimeDifferenceAndGrace()) - Like sliding join windows boundaries are aligned to the record timestamps (as opposed to timestamp) and boundaries are inclusive.
- Records will fall within the same window, if the difference between their timestamps is within the specified window size.
- Sliding Windows with “time difference” and “grace” (
Ordering
Kafka does guarantee events will always be in “offset” order of partition level. Consumers always read events in same sequence that they were appended to the topic (ascending). Unbounded event streams may not always be in “timestamp” order especially for event-time semantics. Events are sometimes delayed. A record with certain timestamp does not always mean that all preceding records consumed. There exists a tradeoff between waiting a certain amount of data (completeness) and propagating updates, even incomplete, downstream immediately (reducing latency). Latency optimization is possible in KS API using continuous refinement. Whenever a new event is added to the window, KS app will emit new window computation immediately.
Handling Delayed Data
With continuous refinement each result should be seen “potentially” incomplete. An emitted event does not mean that every record in window have processed. Delayed data can continue causing events to be emitted at unexpected times. It is possible to apply some methods for minimizing the effect of delayed data on processing:
- Grace Period: With configuring window size and a grace period it is possible to keep window open for a defined amount of time to admit delayed and unordered events in time. After the grace period passed records are discarded.
- Suppression: It solves problem of emitting intermediate results in windowed aggregation.
suppress()operator is used to only emit final computation of window, and to hold intermediate computations temporarily in memory.
Interactive Queries
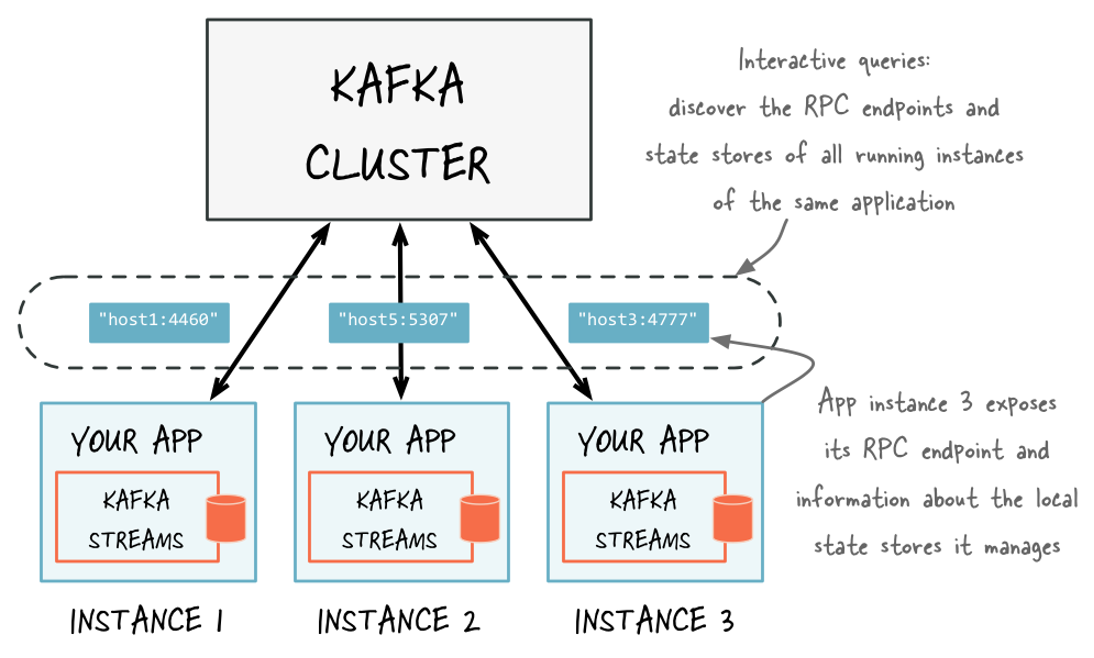
Kafka Streams API has enables to implement a stream processing layer that can be utilized as a lightweight embedded database. The latest state can directly be queried via endpoints (e.g. RESTful WS) exposed by KS micro apps. But the problem is if one uses KTable for materialization the microservice that handles the request may not respond with value for queried key as local state only represents a partial view of the entire application state which in fact is the nature of a KTable. Interactive queries feature of KS API enables to get value for a given key event it does not exist on local KTable as it enables to use Kafka as a service discovery engine to find the KS app that hosts that key-value pair using metadata stored on Kafka (Sample Code).
What is next?
This is the second part of Apache Kafka article series. The next one is about another niche technology in Apache Kafka ecosystem: ksqlDB. It is the Kafka native database for stream processing applications that streamlines to build stream processing applications with a SQL like interface.
References
- Mastering Kafka Streams and ksqlDB, Mitch Seymour
- Apache Kafka Documentation, https://kafka.apache.org/documentation
- Confluent Kafka Documentation, https://docs.confluent.io/home/overview.html