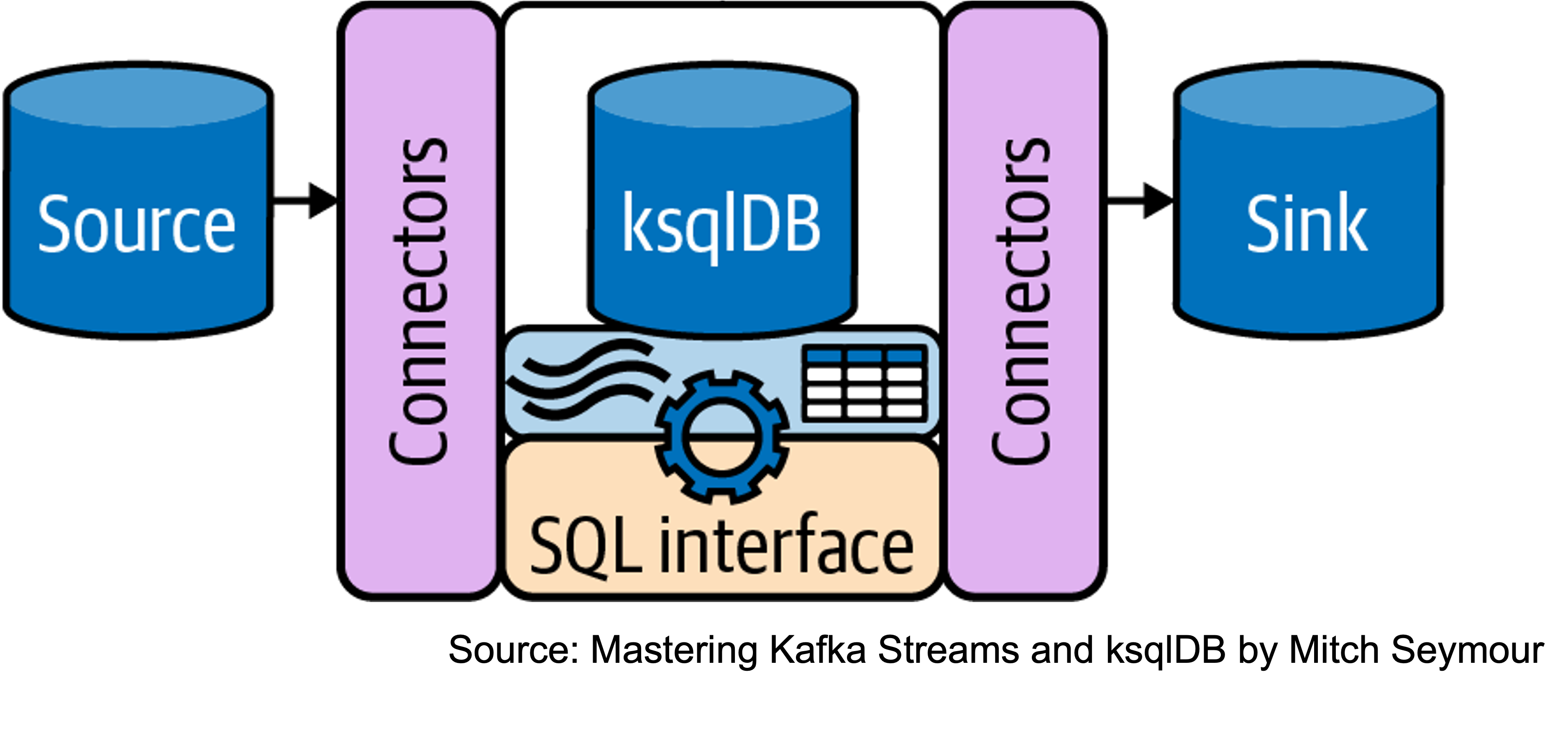
ksqlDB is the OpenSource Kafka native database for stream processing applications that streamlines to build stream processing applications with a SQL like interface to. It aims to streamline building stream processing applications with a high-level SQL-like interface. ksqlDB amalgamates Kafka Streams for stream processing and Kafka Connect to collect event from various data sources. Kafka Connect streamlines to move data into and out of Kafka with a connector ecosystem. For example, it is possible to persist events to a JDBC compliant database using JDBC Sink Connector and to transform data on a JDBC compliant database to a Kafka record using JDBC Source Connector.
The Benefits
ksqlDB has the ability to apply stream processing constructs like join, aggregate, transform, filter, windowing with its SQL-like syntax and without writing JVM code. These SQL statements are compiled into Kafka Streams applications under the hood. The ksqlDB SQL engine parses SQL statement, converts it to KS topologies and runs resultant KS app(s). Parser uses ANTLR to convert SQL statement into Abstract Syntax Tree (AST) where:
- Each node in tree represents a recognized phrase or token in SQL statement.
- Parser builds relevant KS topology using token it finds, e.g.:
| SQL | KS API |
|---|---|
WHERE |
filter() |
LEFT JOIN |
leftJoin() |
The learning curve is shallow as familiarity on SQL is more prevalent than Kafka Streams API. With SQL it requires less code to express a streaming application that boosts productivity and streamlines testing. The declarative and standardized syntax of SQL enables consistency over projects. Less coding with a declarative language eases to explore records in topics and having materialized views. As its’ core and architectural components (Kafka Streams, Kafka Connect) are built on JVM stack, cross-platform deployments become easy. Following kSQL creates a source connector that periodically imports data from users table of a PostgreSQL schema into Kafka topic named jdbc-users:
CREATE SOURCE CONNECTOR `jdbc-connector` WITH (
"connector.class"='io.confluent.connect.jdbc.JdbcSourceConnector',
"connection.url"='jdbc:postgresql://localhost:5432/my.db',
"mode"='bulk’,
"topic.prefix"='jdbc-’,
"table.whitelist"='users’,
"key"='username');
ksqlDB comes with built-in CLI and REST interfaces for executing commands and queries in an interactive way.
CLI:
ksql> SELECT USERID, COUNT(*) AS task_count
>FROM task_stream
>GROUP BY USERID EMIT CHANGES;
+----------------------------------------+---------------+
|USERID |TASK_COUNT |
+----------------------------------------+---------------+
|sdone |8 |
|jsmith |9 |
|sdone |9 |
|jsmith |10 |
>CTRL+C
Query terminated
REST call:
fetch(`http://${window.location.hostname}:8088/query`,
{
method: 'post',
headers: {
"Content-Type": "application/vnd.ksql.v1+json; charset=utf-8",
"Accept": "application/vnd.ksql.v1+json"
},
body: JSON.stringify({
ksql: 'SELECT USERID, COUNT(*) AS task_count FROM task_table GROUP BY USERID EMIT CHANGES;',
streamsProperties: { 'ksql.streams.auto.offset.reset': 'earliest' }
})
});
Even ksqlDB offers lots of benefits, it does not completely replace the need for Kafka Streams. SQL falls short to implement complex logic and use-cases where imperative logic is needed rather than declarative logic.
Similarities and Differences with RDBMS
As the name tells itself, ksqlDB has its roots on database systems especially on Relational Database Systems (RDBMS). It has an SQL interface with the support of DDL and DML statements. It accepts commands and queries over network via clients on CLI, REST and Java API. It is possible to generate schemas and user-defined types. SQL statements can also be enriched via built-in functions on mathematical, string manipulation, time, table, geo-spatial domains. For fault-tolerance and resiliency it has the ability to perform data replication using Kafka under-the hood. Multiple ksqlDB instances in a cluster can process and read shared statements that are written on command topic of Kafka cluster.
ksqlDB outperforms classical RDBMSs as it provides the capability to model and query real-time data streams by establishing stream, table duality via its enhanced DDL, DML statements. At its heart, it bridges bounded data sets (tables) and un-bounded data sets (streams). With the push queries (will be explained soon) mechanism, it can execute continuous queries on unbounded event streams with emitting results and updates of statements that it is ordered to execute. As a first-class-citizen of Kafka ecosystem it can integrate with Schema Registry for schema management that enables schema versioning, compatibility validation, transmission optimization via serialization protocols (e.g. Avro, ProtoBuf), data/type inference and data model consistency over implementations that benefit from ksqlDB. Utilizing HA, fault-tolerance, failover capabilities of Kafka cluster is another advantage for system reliance. With the underlying Kafka Streams usage, it is possible to have materialized/local snapshot of data on remote storage which is Kafka cluster in fact. Co-location of compute node and data (KS state stores) is more performant. Another performance benefit is that the storage layer can be scaled independently from DB engine via scaling Kafka cluster up.
The main difference between ksqlDB and RDBMS is consistency model of transactions. ksqlDB uses eventual consistency that it derives from Kafka. On the other hand, RDBMS implements ACID (atomicity, consistency, isolation, durability) model. Hence, while developing products with ksqlDB this difference should be taken into consideration. The following cartoon depicts eventual consistency wisely:
Eventual Consistency pic.twitter.com/2dMrtfDGAW
— Greg Young (@gregyoung) March 2, 2019
Deployment Modes
ksqlDB supports interactive and headless deployment modes. Interactive mode is the default mode and accepts command and queries via REST API and CLI. These command and queries are written a topic on Kafka named as command. It is possible to generate streams, tables, queries, and connectors using this mode. In headless mode interactive clients are disabled and ksqlDB reads a file set in queries.file config to execute one-off queries and commands. ksqlDB can utilize Kafka Connect instance bundled with it or an external one. In a ksqlDB cluster multiple ksqlDB instances with same ksql.service.id acts as a consumer group.
Query Types
There exists two type of queries designated in ksqlDB:
-
Push Queries: Push queries is used to query streams and tables asynchronously. They run continuously and emit/broadcast results to clients subscribed on them whenever an update occurs on event stream:
ksql> SELECT USERID, COUNT(*) AS task_count >FROM task_stream >GROUP BY USERID EMIT CHANGES; +----------------------------------------+---------------+ |USERID |TASK_COUNT | +----------------------------------------+---------------+ |sdone |8 | |jsmith |9 | |sdone |9 | |jsmith |10 | >CTRL+C Query terminatedThe result of this statement isn’t persisted in a Kafka topic and is printed out only in the console, or returned to the client until it is terminated. Push queries are not shared. If multiple clients execute same statement, ksqlDB emits disparate results to each client. The best practice is to use push queries for transient use cases that does not require state via simple
SELECTs. - Pull Queries: They are short lived and synchronous queries. They used to generate materialized views from streams and tables. These views can be queried by clients akin to keyed-lookups in SQL DBs.
- Persistent Queries: These results for persistent queries are write back to Kafka that survives ksqlDB restarts. There is two types of query structures to utilize these type of queries:
- CSAS:
CREATE STREAM AS SELECT→ This can be used for deriving persistent queries for streams. - CTAS:
CREATE TABLE AS SELECT→ This can be used for deriving persistent queries for tables.CREATE OR REPLACE STREAM user_stream ( ROWKEY VARCHAR KEY, FIRSTNAME VARCHAR, LASTNAME VARCHAR ) WITH ( KAFKA_TOPIC = 'users', VALUE_FORMAT = 'AVRO', PARTITIONS = 3, REPLICAS = 3 );
- CSAS:
Join Types
ksqlDB can be utilized to merge different real-time streaming data flows via SQL’s JOIN statement. This join is alike join in RDBMS as they both combine data from two or more sources based on common values. ksqlDB supports following join types:
| Join Type | Supported Joins | Any time constraint (windowing) required? |
|---|---|---|
| Stream-Stream | Inner, Left, Full | Yes |
| Stream-Table | Inner, Left | No |
| Table-Table | Inner, Left, Full | No |
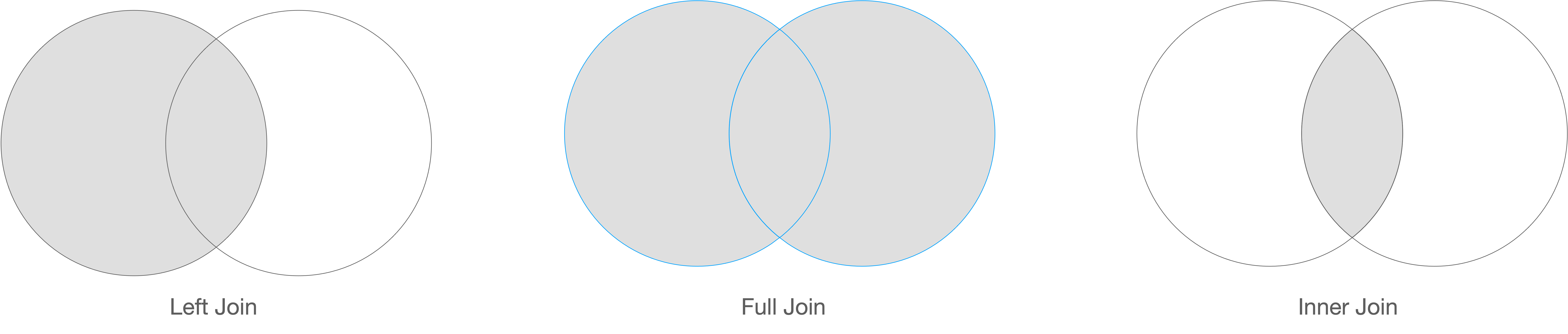
Following constraints apply on joins:
- All columns referenced in join expression must be in same data type.
- Partition count on each side of join must be same.
- Same partitioning strategy must be used in producers (def. hash based).
Time and Windows
Each record on ksqlDB denotes an immutable representation of an event in time and has a timestamp (ROWTIME column) that denotes its position on time axis (based on UTC timezone):
ksql> SELECT ID, USERID, STATUS, TIMESTAMPTOSTRING(ROWTIME, 'dd-MM-yyyy HH:mm:ss.SSS')
>AS timestamp FROM task_table EMIT CHANGES;
+-------------------------------------+-----------+---------------+------------------------+
|ID |USERID |STATUS |TIMESTAMP |
+-------------------------------------+-----------+---------------+------------------------+
|a1c6a615-3bbe-4f3e-b48a-6b2b6df5c7e8 |ccole |ASSIGNED |28-07-2021 08:18:52.027 |
|40881367-bb6c-4653-adaa-ad2b12f307e6 |jsmith |COMPLETED |28-07-2021 08:19:09.092 |
|c3b5086a-5490-4d95-9968-a49cfe64556c |jsmith |ASSIGNED |28-07-2021 09:21:40.604 |
|9808838d-b5d6-4e88-bf9a-f7a297e17eac |jsmith |ASSIGNED |29-07-2021 16:10:18.337 |
|e305110a-b61a-4160-8598-e0020344a5e0 |jsmith |ASSIGNED |29-07-2021 16:10:40.578 |
|0cd40a7a-4005-47a2-a6ed-292df24ddf50 |rdark |ASSIGNED |29-07-2021 16:18:48.214 |
Timestamp is set according to topic configuration (message.timestamp.type parameter) with following two options:
- CreateTime: Time when event is sent by producer
- LogAppendTime: Time when event is ingested by Kafka broker
Timestamps are modified for aggregations and joins:
- Stream-stream, table-table joins →
max(left.ts, right.ts) - Stream-table join → timestamp of stream record
- Aggregations → max timestamp is computed over all records, per key (globally or per-window).
ksqlDB generates WINDOWSTART and WINDOWEND columns for results of windowed queries:
ksql> SELECT USERID,
>TIMESTAMPTOSTRING(WINDOWSTART, 'dd-MM-yyyy HH:mm:ss') AS Window_Start,
>TIMESTAMPTOSTRING(WINDOWEND, 'dd-MM-yyyy HH:mm:ss') AS Window_End,
>COUNT(*) AS task_count FROM tasks
>WINDOW TUMBLING (SIZE 15 MINUTES)
>GROUP BY USERID HAVING COUNT(*) > 3
>EMIT CHANGES;
+--------------+----------------------+----------------------+--------------+
|USERID |WINDOW_START |WINDOW_END |TASK_COUNT |
+--------------+----------------------+----------------------+--------------+
|ccole |30-07-2021 09:30:00 |30-07-2021 09:45:00 |5 |
|ccole |30-07-2021 09:30:00 |30-07-2021 09:45:00 |6 |
|ccole |30-07-2021 09:30:00 |30-07-2021 09:45:00 |8 |
|ccole |30-07-2021 09:30:00 |30-07-2021 09:45:00 |9 |
|ccole |30-07-2021 09:30:00 |30-07-2021 09:45:00 |11 |
|jsmith |30-07-2021 09:30:00 |30-07-2021 09:45:00 |4 |
|jsmith |30-07-2021 09:30:00 |30-07-2021 09:45:00 |6 |
|jsmith |30-07-2021 09:30:00 |30-07-2021 09:45:00 |7 |
|jsmith |30-07-2021 09:30:00 |30-07-2021 09:45:00 |8 |
|jsmith |30-07-2021 09:30:00 |30-07-2021 09:45:00 |9 |
For session windows, if window contains:
- only 1 record: WINDOWSTART=WINDOWEND=ROWTIME
- > 1 record:
- WINDOWSTART = ROWTIME of earliest
- WINDOWEND = ROWTIME of latest
ksql> SELECT USERID,
>TIMESTAMPTOSTRING(WINDOWSTART, 'dd-MM-yyyy HH:mm:ss') AS Window_Start,
>TIMESTAMPTOSTRING(WINDOWEND, 'dd-MM-yyyy HH:mm:ss') AS Window_End,
>COUNT(*) AS task_count FROM tasks
>WINDOW SESSION (5 SECONDS)
>GROUP BY USERID
>EMIT CHANGES;
+-------+---------------------+---------------------+-------------+
|USERID |WINDOW_START |WINDOW_END |TASK_COUNT |
+-------+---------------------+---------------------+-------------+
|ccole |30-07-2021 10:08:02 |30-07-2021 10:08:02 |1 |
|ccole |30-07-2021 10:08:12 |30-07-2021 10:08:12 |1 |
|ccole |30-07-2021 10:08:12 |30-07-2021 10:08:15 |2 |
|ccole |30-07-2021 10:08:12 |30-07-2021 10:08:17 |3 |
|ccole |30-07-2021 10:08:12 |30-07-2021 10:08:20 |4 |
|ccole |30-07-2021 10:08:29 |30-07-2021 10:08:29 |1 |
|ccole |30-07-2021 10:08:29 |30-07-2021 10:08:34 |2 |
|ccole |30-07-2021 10:08:29 |30-07-2021 10:08:37 |3 |
|jsmith |30-07-2021 10:09:54 |30-07-2021 10:09:54 |1 |
|jsmith |30-07-2021 10:09:54 |30-07-2021 10:09:57 |2 |
|sdone |30-07-2021 10:10:00 |30-07-2021 10:10:00 |1 |
|sdone |30-07-2021 10:10:05 |30-07-2021 10:10:05 |1 |
|sdone |30-07-2021 10:10:05 |30-07-2021 10:10:09 |2 |
|ccole |30-07-2021 10:10:14 |30-07-2021 10:10:14 |1 |
|jsmith |30-07-2021 10:10:16 |30-07-2021 10:10:16 |1 |
|sdone |30-07-2021 10:10:19 |30-07-2021 10:10:19 |1 |
|rdark |30-07-2021 10:10:22 |30-07-2021 10:10:22 |1 |
|ccole |30-07-2021 10:10:40 |30-07-2021 10:10:40 |1 |
|jsmith |30-07-2021 10:10:43 |30-07-2021 10:10:43 |1 |
|ccole |30-07-2021 10:10:40 |30-07-2021 10:10:45 |2 |
|jsmith |30-07-2021 10:10:48 |30-07-2021 10:10:48 |1 |
A tumbling window with grace period:
ksql> SELECT USERID,
>TIMESTAMPTOSTRING(WINDOWSTART, 'dd-MM-yyyy HH:mm:ss') AS Window_Start,
>TIMESTAMPTOSTRING(WINDOWEND, 'dd-MM-yyyy HH:mm:ss') AS Window_End,
>COUNT(*) AS task_count FROM tasks
>WINDOW TUMBLING (SIZE 5 SECONDS, GRACE PERIOD 2 SECONDS)
>GROUP BY USERID
>EMIT CHANGES;
+-------+--------------------+--------------------+------------+
|USERID |WINDOW_START |WINDOW_END |TASK_COUNT |
+-------+--------------------+--------------------+------------+
|ccole |30-07-2021 10:21:20 |30-07-2021 10:21:25 |1 |
|ccole |30-07-2021 10:21:20 |30-07-2021 10:21:25 |2 |
|ccole |30-07-2021 10:21:30 |30-07-2021 10:21:35 |1 |
|ccole |30-07-2021 10:21:40 |30-07-2021 10:21:45 |1 |
|ccole |30-07-2021 10:21:40 |30-07-2021 10:21:45 |2 |
|ccole |30-07-2021 10:21:45 |30-07-2021 10:21:50 |1 |
|ccole |30-07-2021 10:21:45 |30-07-2021 10:21:50 |2 |
|ccole |30-07-2021 10:21:50 |30-07-2021 10:21:55 |1 |
|ccole |30-07-2021 10:21:50 |30-07-2021 10:21:55 |2 |
|ccole |30-07-2021 10:21:55 |30-07-2021 10:22:00 |2 |
|ccole |30-07-2021 10:21:55 |30-07-2021 10:22:00 |3 |
Conclusion
Even emerged as a messaging platform, Apache Kafka is now a distributed event streaming technology used by myriad of organizations1 and teams to build high-performance, resilient, fault-tolerant data buses to have knowledge and insight via real-time analytics and data integration. Obviously, it is not possible to summarize Apache Kafka in a three parts article. The best way to comprehend such a state-of-art technology is to read the official documentations, books by experts and most importantly to apply/practice the theory with setting up a basic cluster and coding against it. The references part of each article lists valuable resources that paved the way of my Apache Kafka journey and writing this article series.
And as always, there exists a sample project on GitHub that I aimed to touch most of the aspects of Apache Kafka. This project is an event driven task management application that comprises of PostgreSQL DB and ReactJS, Apache Kafka, Kafka Streams (based on single writer principle) and the major ecosystem components like SchemaRegistry, Kafka Connect. The UI is based on ReactJS and Bootstrap. Keycloak with OpenLDAP is used as IdP (Identity Provider) to enable OAuth2 and OIDC driven AAA (AuthN, AuthZ, Accounting). The Kafka Stream source, processor and sink implementations are based on Spring Cloud Stream Kafka Binder.

References
- Mastering Kafka Streams and ksqlDB, Mitch Seymour
- Apache Kafka Documentation, https://kafka.apache.org/documentation
- Confluent Kafka Documentation, https://docs.confluent.io/home/overview.html
- ksqlDB Documentation, https://docs.ksqldb.io/en/latest/
-
https://kafka.apache.org/powered-by ↩