Just like our immune systems are being tested by the novel Coronavirus nowadays, digital channels are being tested in various ways. Getting them and their users securely access to resources is becoming a more and more daunting task. That is why new methodologies/technologies are still emerging besides traditional methods like “basic authentication, form login, certificate authentication, cookie validation”.
Today the ease of access to internet and the smart devices paves the way utilizing digital channels increasingly for fulfilling daily needs. Organizations are adding vast amount of business capabilities on them to align with this trend fueling their digital transformation efforts. The prevalence of mobile applications, JavaScript based Single Page Web Applications (SPA) and the technological advancements on platforms (smart devices, browsers, etc.) that host them results in more API (Application Programming Interface)-led solutions and end user clients are being implemented.

Most of us have identities on social media and digital services platforms. These platforms started to act as identity providers that enables users to use their existing identities or to delegate them to access other online services or platforms. The decoupling of identity source and the application requires a new way to exchange the authentication and authorization information between these systems. An answer to this problem is OAuth which introduces a way to use a digital token as a key to access the APIs exposed by these applications. As OAuth specification mostly tried to address authorization of access requests since day 1 another specification named as OIDC (OpenID Connect) introduced as an authentication layer on top of OAuth.
The Need for a New Method
There exists various authentication and authorization methods such as basic authentication, Kerberos, SAML (Security Assertion Markup Language), certificate authentication, API keys. Most of the existing systems have been making use of them for several years. In order to handle huge amount of transactions reliably modern systems became more architecturally decoupled in terms of both inner and client and server (resource) aspects and the identity providers became a mediation layer between these technology services. So, the identity brokers need to ensure privacy, usability, security at scale in a flexible and reliable way. Aforementioned identity and access methodologies are massively being used and will ultimately be utilized until the time the last legacy solution embraces them is decommissioned. However, they fell short of to meet current needs of modern systems and a new methodology was needed to handle authentication, authorization and provisioning of digital identities. Such as;
Basic Authentication
As the name tells itself it is the basic and one of the oldest methods of authentication where user credentials are provided directly or with an authorization header that consist of base64-encoded username:password combination preceded by Basic word and a space in case of HTTP communication. In order to avoid interaction with end-user again and again the client needs to store credentials on account of reuse. This may turn out to be a significant shortcoming as the credentials can be compromised in message interchange or in the application’s memory. There were initially some cases that some 3rd party service providers requested users to access resources which prevents them to revoke access rather than changing their own credentials, if the user is lucky enough to change it before anyone else, in case of any breach.
In a nutshell, having the user’s credential enables client application to act as user at all means.
Kerberos
Kerberos uses an access identifier named as “ticket” for access management. In order to request ticket clients need to access Key-Distribution Center (KDC), which is located on the domain controller. These tickets are only valid at domains that the controllers belong to. So, it is hard to scale between different zones, deployment models. In case
SAML (Security Assertion Markup Language)
With version 2.0 SAML become more prevalent as an inter-domain authentication protocol. Even it supports browser-based authentication, it does not fulfill modern requirements such as consent management and API based access to resources from systems such as mobile apps and other services. It is also hard to process XML based assertion data for mobile and SPA clients.
API Keys
This method facilitates to consume API based business capabilities where access keys are generated via API portals for application developers. Developers are responsible for storing and maintaining these keys. Generally these keys are embedded in application code or in vaults. In case of any breach, these keys can be used during their lifetime by anyone for access.
Certificate Authentication
It builds the authentication on certificate exchange between systems. This puts additional burden on enterprises to manage life-cycle of keys (generate, store, etc.) used for signing the certificate and life-cycle of certificates (generate, revoke, etc.) itself. In the case of SSL/TLS termination the certificate validation for end-to-end authentication needs to be handled at application layer by load balancers, web application firewalls (WAF), applications. That means additional challenge as it is done at transport layer by default without any intervention.
The Triple A (AAA) - Authentication, Authorization, Accounting
AAA is the term that summarizes tasks need to be performed in order to access data, resources and systems in a secure, controlled and monitored manner.
Authentication
In order to access a system, it is required to verify the identity of the user in the first step, in other words, to check whether it provides a valid key (user name & password, access key, etc.) defined in the identity management system or application and thus the user should be identified. This task is named as authentication. The success of authentication depends on certain rules defined in security domain. The identity management system or security software in the application compares the credentials provided within user request. If they match, access is granted. Otherwise, authentication fails and access is denied.
Authorization
After the authentication task, it is required to determine what actions and operations that the authenticated user can perform in the system or application or which resources that user can access. In summary, it is the stage to apply the access policy defined for users by organizations or authorities.
Accounting
During the course of access various metrics need to be collected, such as the duration of authentication and authorization, session time, usage count, data and request traffic between users and system, so on and so forth. For this purpose, statistical information is compiled via event logs on systems and they are used for billing purposes, resource consumption, usage trend and system engineering, capacity utilization evaluations.
OAuth
As previously stated a new method so that a new access protocol was needed due to the shortcomings of existing methods. OAuth, an open protocol, has emerged from the web, mobile and desktop applications to provide secure authorization control in a simple and standard way. It is again worth underlining that due to its nature OAuth is a protocol which defines authorization in an AAA process. Organizations tried to overload this with authentication function, and developed their own adaptations which started to derail the OAuth standard. The OpenID community saw this and developed a new specification named as OpenID Connect that sits on top of OAuth to address the authentication functionality gap. The OAuth protocol, version 2.0 released on the date of this writing, has become an industry standard for authorization. The protocol is basically described by the RFC 6479 standard published in October 2012, and its specifications and additions are developed by the OAuth working group within the IETF.
The OAuth Terminology
Due to its increasing popularity there are lots of online resources on OAuth that may easily drive developers and architects into confusion. Because the specification is comprehensive and it is interpreted differently by different people. Therefore, in order to better explain the protocol, it is worth to elaborate some basic concepts that are also listed in the RFC document:
- Resource Owner: It refers to the owner of a resource kept digitally in a secure environment or the entity authorized to access this resource. Essentially, this is an end user who interacts with systems via client applications. Client: It refers to the application that is delegated to access the resources owned or accessible by resource owner. In order for any application to fall within the scope of this definition, it is sufficient to perform the requests made to the source under protection and it does not differ conceptually whether it is technologically on the server or in one of the different user interface forms (mobile application, web browser, kiosk, etc.).
- Authorization Server: It refers to the system or software that handles the request of the client to access the source, creates the access token required for access after completing the authentication and authorization tasks successfully, sends it back to the client for use, checks the validity of a given token if requested and also manages its life-cycle.
- Resource Server: It refers to the system or software that contains the resources itself or the access ability to them, and verifies and responds the access requests using accompanying access token. This verification can be done by contacting the authorization server in a different environment or within the authorization server itself and there is no standard definition in RFC 6479 for that.
- Access Token: It refers to the string provided by the authorization server, which documents the resource owner’s authorization to access resources. Although a standard on the format of this has not been determined yet in the RFC document, there are authorization server solutions which generate them in JWT (JSON Web Token) format. Generally this token is in non-human readable, alphanumerical format, but it may actually consist of a character string formed by a human-readable format (e.g. JSON) encoded with a method such as base64 as in JWT. The data payload carried on access token comprises information such as the scope of access allowed by the resource owner and the maximum duration of the session. The client passes the token to resource server with an Authorization header, and the resource server validates the request with this information. There authorization server also generates a refresh token which is used to extend the renewal/validity of the access token. However, the use of refresh tokens by SPAs can result in the new access tokens are being produced by unauthorized clients, especially because of their longevity and the fact that they cannot be stored in a safe environment. However, for the use of applications that need automatic renewal of the session, there are client libraries that perform this operation in the background via a hidden iframe with the “silent refresh” method.
-
Authorization Grant: It refers to the credentials of the Resource Owner to obtain the access token. This can be a combination of username & password provided by the resource owner via a login form, or authorization code, or a credential defined by the client.
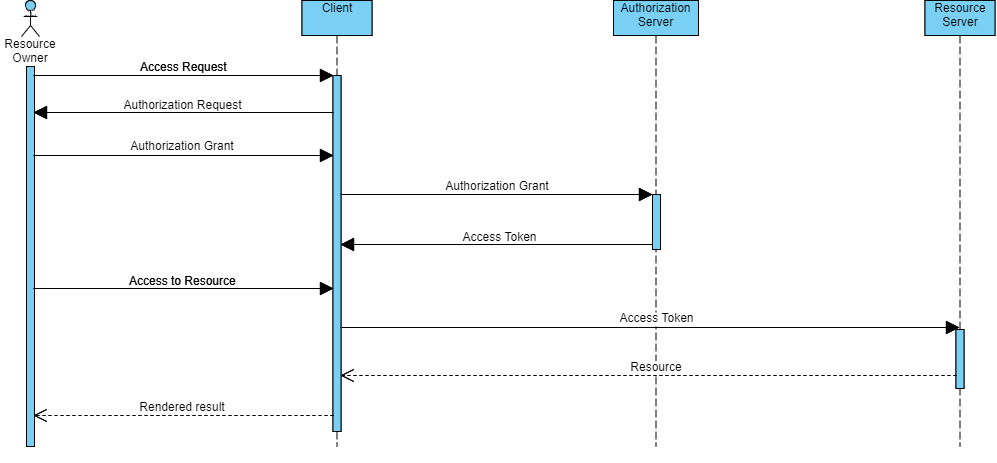
-
Redirection Endpoint/URI: As can be seen in figure above, in basic OAuth authorization flow (OAuth dance) the credentials received from resource owner is passed to the authorization server by client and then authorization server redirects the client back to the redirection endpoint/URI address configured on the authorization server. Thus, the client acting as an intermediary manages two different interactions together: resource owner to client and client to authorization server. It also provides an additional security function to prevent unauthorized applications to accessing the token. However, in order to make this useful, it is necessary to make the relevant configuration on the authorization server with the URI value/pattern of the relevant applications that is intended to be fully routed instead of wildcard (*) alone:

-
Scope: Each client needs to send the scope of access that are requested through authorization server. The authorization server then generates and sends the access token according to the client-specific configurations on it. However, if there is a configuration in the authorization server that the consent requirement should be sought for the relevant client, the server directs the client to a consent screen accordingly and continues the flow according to the resource owner’s permission. Consent activation is generally meaningful when using an authorization / identity management solution that is not controlled by the organization. If the created token scope is different from the scope requested by the client, the authorization server adds the “scope” parameter in the response to inform the client about the actual access scope configured for it. If the client skips the scope parameter while requesting authorization, the authorization server processes the request using the default scope values defined for the client, or denies the access request if an invalid/not-configured scope is requested. Scope actually helps to verify the level/type of access that the client requests on behalf of resource owner. In other words, it should not be used for authorization on the resource server. Instead, the attributes and roles defined for the user or the groups that the user belongs to in a user database or a user directory solution should be used on the authorization server. That is why most of the authorization server solutions provides user federation functions that enables to integrate with external user databases such as LDAP (Lightweight Directory Access Protocol) compliant directories and Active Directory.
OAuth Flows
The OAuth standard defines different messaging patterns, named as flows, that correspond to different types of clients/use cases among the actors/technology components to ensure secure access to resources and enabling authorization. OAuth compliant authorization server solutions support these standard flows and expects a parameter (response_type) is to be set by client within the request to decide which flow needs to be executed. Some common flows are as follows:
Authorization Code
It is one of the widely used flow types. Here, when the identity and authorization verification is successful for the client, a code (code) with very short validity period is created by the authorization server and it redirects the client to the defined redirect URI with this code. Then, access token is requested from the authorization server with this code, and after the code verification is done the authorization server sends the access token that the client will use in its interaction with the resource server. This method is especially useful for clients with a web backend. With the help of this flow, the access token which is the critical key that unlocks the resource gate is not directly sent to client where it can be obtained easily (via developer tools on the browser, URL parameters, source codes, etc.) and can be used for unintended purposes. Instead the code sent to client is passed to the web server which is hosted in a more secure environment. Then, the web backend goes to the authorization server with this code and requests the access token. This authorization code has three tenets that hardens security rather than using access tokens directly:
- It’s temporary and valid for a short while.
- It is only a parameter for token request, not used for access to resource.
- Communication between the web backend and the client can be maintained using a traditional cookie or session-based methods.
Authorization Code + PKCE
As mentioned in the introduction, SPA and mobile applications and their access to the offered business capabilities/resources are becoming more and more common through APIs. When it comes to clients in the form of SPA, the static content (HTML, JavaScript, images, page styles or CSS) that shapes the web page are generally loaded at a time and rendered by browsers from web servers that neither host a business logic and nor provide session management. Therefore, the authorization code flow mentioned in the previous section cannot guarantee secure application/ resource access alone, since both authorization code and access token become visible on the browser.
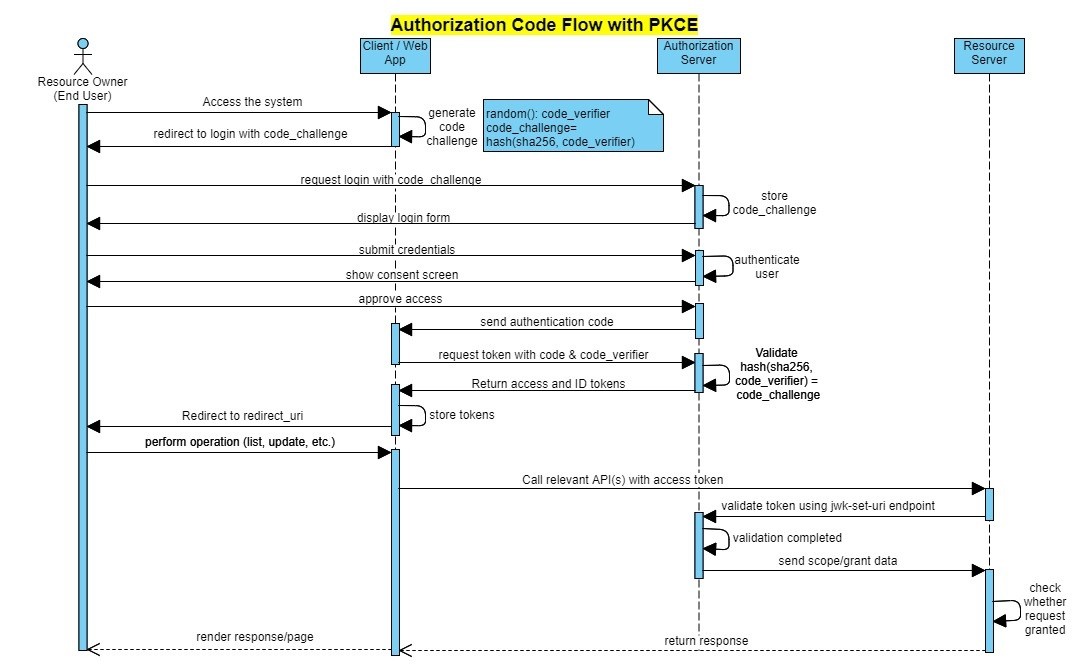
Nevertheless, authorization code flow, one of the most reliable and common flows in OAuth flows, has not been put aside. An extra security mechanism besides authorization code has been added on it, which results in Authorization Code + PKCE (Proof Key for Code Exchange) flow. It is now the suggested method by OAuth community for SPA clients. This flow, which has its own standard definition (RFC 7636), adds a validation measure to close the mentioned gap: a key dynamically generated at the beginning of the flow. Thus, it is aimed to avoid relying on a single a key which is valid for a certain period of time.
In fact, the PKCE method has been used in mobile and native apps for a while. Until recently, both the browsers and many access management solution providers do not support this method due to lack of technology functions such as browser history, local storage, cross-site POST requests. Today both browsers and identity providers overcame these restrictions and PKCE is also in action for SPAs. Basically, PKCE requires creating a random string (code verifier) by the client application then hashing it according to a cryptographic hash algorithm (mostly SHA256) and transmitting the new character string (code challenge) to the authorization server. Then, the authorization server stores the code challenge value after authentication and when it receives the request for the access token from the client, it also expects for the code verifier string. When this information arrives, the authorization server hashes the code verifier with configured hashing algorithm which should be same as client’s one and checks whether it matches code challenge value it stores at the beginning of the flow. If verification is successful, it creates and sends the desired access token to the client. Otherwise, it rejects the request.
Implicit Flow
This flow is designed to enable OAuth usage for JavaScript-based clients due to the constraints mentioned in the previous section. In this flow, there is no additional verification measure after authentication, and the client has the ability to have access token directly and the token is included in the request URLs besides a parameter (access_token). In this flow, the authorization server does not know the authenticity of the client, and it does not have a method to verify whether the token transmitted to the real addressee. In addition, modern web browsers may synchronize the history of the visited web pages with full URLs in another environment or allow the plugins installed on them to follow these URLs. This may cause leakage of critical data such as access token to someone else than the real owner. The PKCE flow mitigates this with the usage of additional secret, code verifier, to hinder the direct usage of access tokens by malicious browser extensions. For these and similar reasons, a directive was issued in November 2018 that implicit flow should no longer be used. This was also included in two different best practice documents (OAuth 2.0 for Browser-Based Apps, OAuth 2.0 Security Best Current Practice) published by IETF.
ROPC Flow
Resource owner password credentials (ROPC) flow, which was defined in the 2012 specification is to enable OAuth for the legacy systems and applications. It basically bypasses the username & password login form of authorization server and enables client directly request access token from authorization server with the credentials of resource owner. Today, it is no longer valid because of the existence of the new generation flows mentioned and the fact that this flow may lead to serious security vulnerabilities (password anti-pattern).
Client Credentials
This flow is designed to request access tokens by applications with their own credentials where there is no an end user interaction and a very limited scope of authority is needed. In fact, this flow is mostly used when the resource owner and client are the same entities and accessing resources through an authorization grant given by the authorization server at a previous stage.
Other Flows
- Device Flow: Used for systems without any user interface (IoT devices, Smart TV, drones, home entertainment systems etc.) through mobile applications.
- Hybrid Flow: Combines implicit and authorization code flows
- SAML Assertion Framework for OAuth: Combines SAML and OAuth at one point to enable retrieval of access tokens with SAML assertions and has a standard definition of RFC 7522.
OpenID Connect (OIDC)
As mentioned in the OAuth section, the OpenID Connect (OIDC) specification has been developed as a complement to mitigate the shortcomings of OAuth, which is originally designed for authorization, in performing the authentication function. In particular, the identity profile and user information (userinfo) of the resource owner, which cannot be accessed with OAuth, become accessible via a REST endpoint (/userinfo) introduced by OIDC specification. OIDC provides this information in a standard JWT (JSON Web Token - RFC 7519) format, which is called ID Token. ID Token content can be viewed through any JWT decoder (e.g. jwt.io):
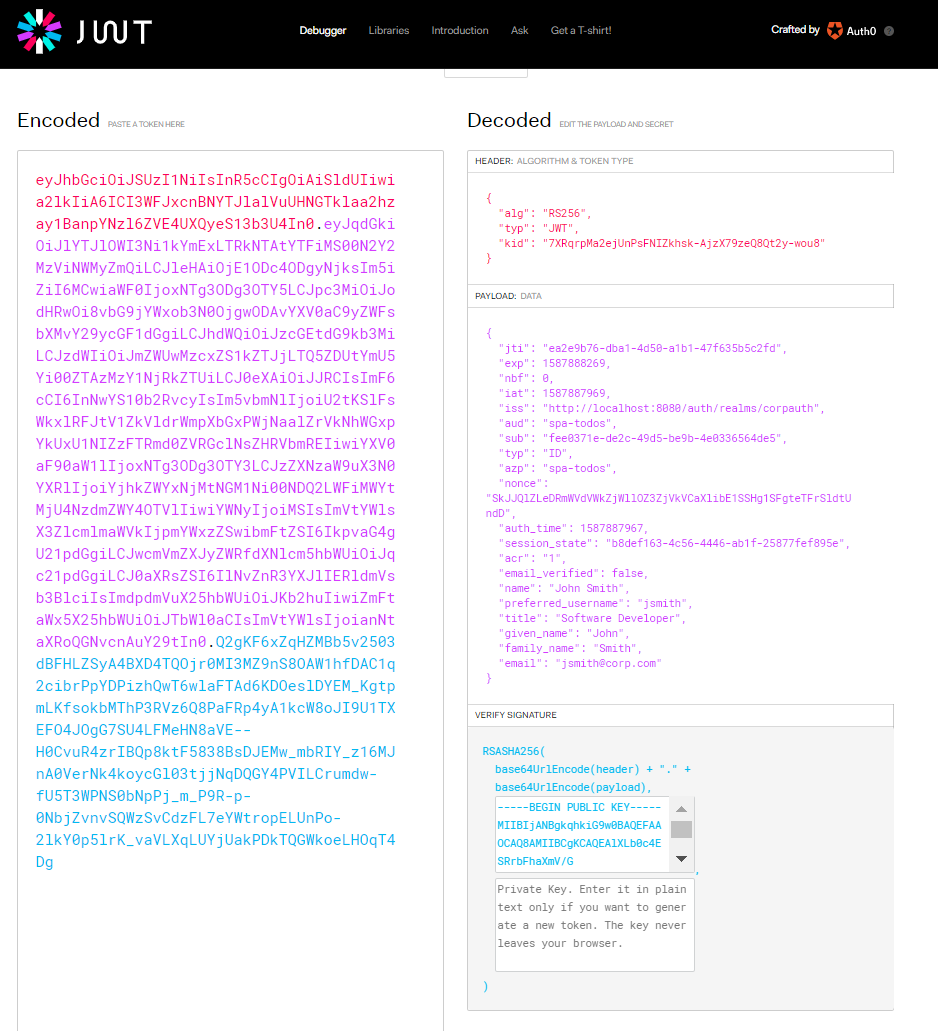
A JWT basically consists of three parts and each part is separated by a period (.) sign. The first section contains information such as the algorithm key ID with which the JWT signature was created, while the second section contains information such as the validity of the token, when and by whom it was created, client definitions, and mainly the resource owner’s user information. In the last part, there is a cryptographic signature created to verify the integrity and authenticity of JWT. This feature of ID token is a good alternative to SAML assertion, which is also used to fulfill this need. Enabling authentication and authorization are to be performed by single identity and access management solution boils down to SSO (Single Sign-On) is to be supported. ID token is a container that comprises user, authentication and identity management system information, and it facilitates to move this information to other systems. Therefore, ID tokens can be used for cross-domain authentication and authorization where SAML is also used extensively. In addition, client applications can have the competence to offer a personalized user experience in their interfaces in line with the resource owner information they obtain from there.
Sample Project
As a simple demonstration of concepts mentioned in this article a GitHub hosted sample project was implemented (Archimate based architecture model below) that utilizes “Authorization Code Flow + PKCE”. It comprises:
- An SPA client implemented by a combination of the well known Angular JavaScript development framework and Polymer Elements based on Web Components specification
- Keycloak, an open source authorization server
- OpenLDAP-based directory server
-
OAuth2 Resource Server that has been implemented with Spring Boot and uses data from the JSON Placeholder test API
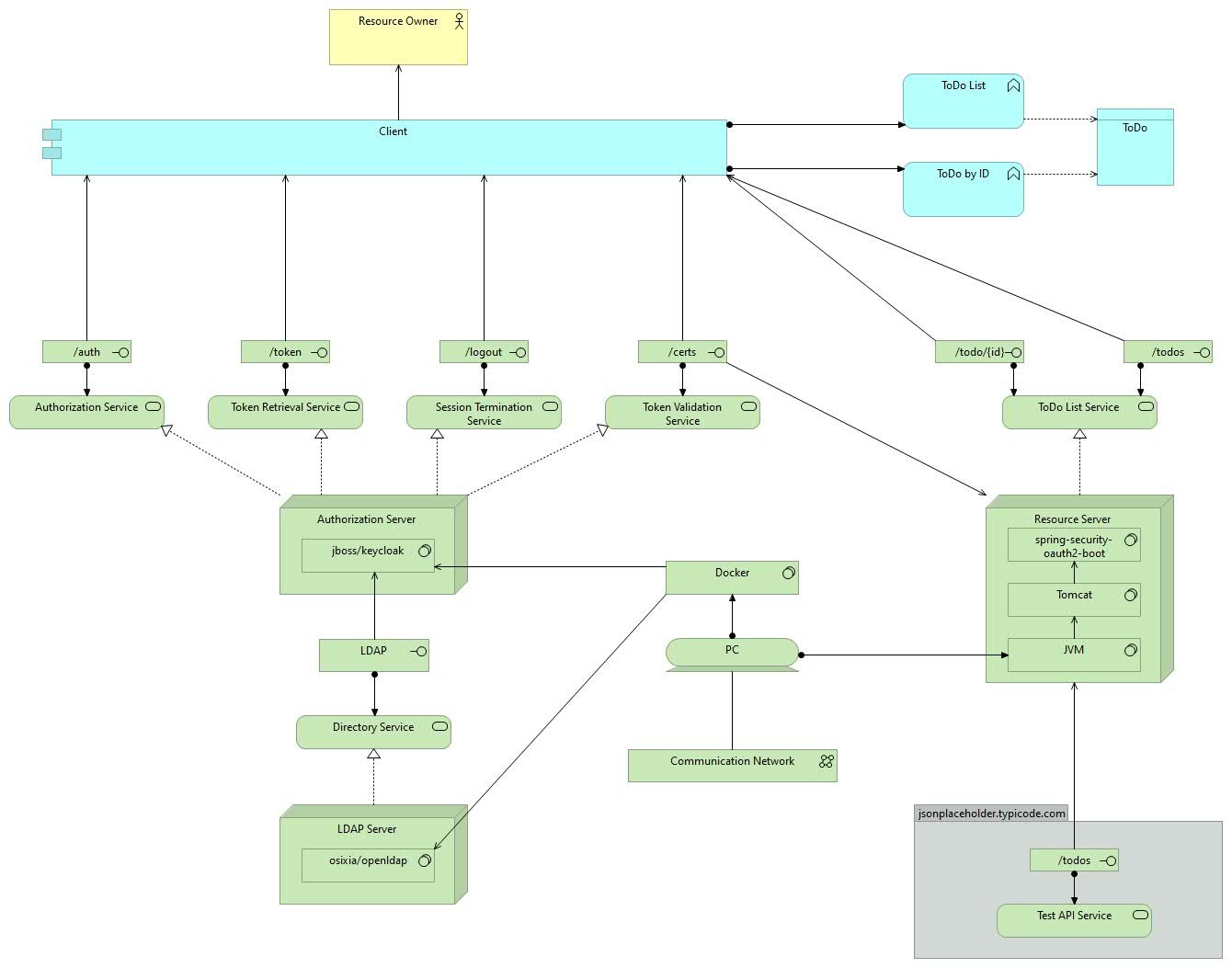
In order not to consume more space here, implementation and configuration details are described in the markdown project documentation. It is worth to underline that one should use libraries and frameworks that have been certified by OpenID, especially in both client and server-side developments. Here, the angular-oauth2-oidc (TypeScript + Angular support) and oidc-client-js (pure JavaScript support) libraries are used in an interchangeable mode, and Keycloak is used for authorization server where these solutions are certified ones. The implementation is entirely based on the protocol specification, and it is solution (authorization server) agnostic (not used vendor specific libraries).
The aim of this project is to have a better understanding on these specifications and a search for conceptual evidence of OAuth & OIDC usage/functionality. In this project, it will be inevitable to have missing/faulty parts terms of both software engineering, application and information security. So, anyone who wants to take this work as a reference should take them into consideration.