TOGAF© describes Technology Architecture as follows:
Develop the Target Technology Architecture that enables the logical and physical application and data components and the Architecture Vision, addressing the Request for Architecture Work and stakeholder concerns. - TOGAF© 9.1
Another interpretation of this statement would be the importance of fulfilling the needs with the right application capabilities that turns data into most meaningful asset nowadays, aka information. Unless underpinned with right technology stack it is very hard to shape a technology architecture that lays the foundation for enterprise architecture (EA). A solid and sustainable EA is the way to support the business vision and to achieve business outcomes that deliver value for customers so that for enterprise.
As an event streaming platform evolved from a publish-subscribe messaging system, Apache Kafka manifests itself as a technology to collect, process, store the data at scale in a performant and reliable way1.
Before delving into Apache Kafka technology one needs to have a solid grasp on the relation between data and information, the concept of event, the drawbacks on client-server model and what event-driven systems bring to mitigate them.
Data is Power
A business produces data at every stage of its lifetime while:
- Introducing a product
- Interacting with its customers
- Delivering value and services to its customers
The global data traffic increased 112 times from 2008 to 2020.2 To unleash the power of such a massive amount of data, it should be transformed into a more meaningful asset, information, using right combination of application and technology stack while specification, monitoring, execution of business processes. Because:
Every company is a technology company, regardless of what business they think they are in. A bank is just an IT company with a banking license. - Christopher Little
This information is then used to gain knowledge in a quick and a straightforward way. It is the primary tool for understanding and overcoming business challenges in fast-paced and ever-changing world.
Event
As stated in the introduction Apache Kafka is a streaming platform that persists and distribute events. An event denotes a change of a state, something happened in a domain or system and it is inherently a time bounded fact. As events are already happened, they are immutable and accumulation of these timed facts reveals behavior of the system or domain that they are generated by. The prevalence of interconnected and smart devices forces global businesses to capture and distill events carried by real-time digital data streams produced by them that mostly wipes out conventional commerce models. In order to gain meaningful insights and knowledge one should react to and process these events whilst storing them. In essence, the enterprises/organizations that can process, enrich, transform, and respond to data incrementally as it is available become the leaders and pioneers in their business.
Client-Server Model (Request-Driven Systems)
During the rise of web era the common design pattern for systems domain was client-server model which is mainly backed by request-driven architecture which is synchronous and blocking in terms of communication and command execution. This is however, became inadequate to handle massive data volumes in a performant way. Because, the systems that embrace this model are tightly coupled. The requestor (client) and responder (server) need to know each other in order to interact each other. The need for such a seam between these actors turns out to be a maintenance and sustaining burden. As communication is synchronous, it leaves little room for error and there is no delivery guarantee in case of target system becomes unavailable, unless there exists a queuing, retrying mechanism in requestor side which contradicts to the simplicity of client implementation.
The variety of event sources (sensors on a plane, IoT devices on lorry fleet, click on an e-commerce site, etc.) also means that the systems that generate them may use different protocols, scaling strategies and error-handling mechanisms. The existence of myriad types of systems and software/technology specifications brings the maintenance and integration effort, so that cost, proportionally.
Generally speaking, these types of systems implements no control on the pace of incoming requests and data streams (e.g. ingress buffer for events). There is no focus on the context and content of data and what is being communicated. The last and may be the most prominent drawback is that the communication between client and server is not replayable. IOW, it is difficult to reconstruct or rollback the state in case of any need.
Apache Kafka
You do not need to leave your room. Remain sitting at your table and listen. Do not even listen, simply wait, be quiet, still and solitary. The world will freely offer itself to you to be unmasked. - Franz Kafka, The Zürau Aphorisms
As one of the prominent writers of 20th century, Franz Kafka underlined the importance of listening to understand things happening around with aforementioned quote of him. Although Jay Kreps, co-creator of Apache Kafka, stated3 that to name a technology optimized for writing he used the name of a writer whom he likes, the above quote also overlaps with Apache Kafka’s function of listening and processing events around.
History
Apache Kafka built at LinkedIn in 2008 by Jay Kreps (technical lead of search systems at that time), Neha Narkhade and Jun Rao. The company open sourced the project in 2010 and it joined under Apache Umbrella in 2011. The team left the company in 20144, and founded a new company named Confluent which provides enterprise event streaming solutions (on-premise and SaaS) on top of Apache Kafka technology. It is used by big tech unicorns like Netflix, Spotify and Uber5.
There existed two main challenges at LinkedIn that the team was asked to overcome:
- Request/transaction monitoring system was faulty and worked with polling model:
- Data points had large gaps.
- Data model was not consistent.
- Maintenance was not straightforward:
- Schema changes had been turned out to be outage.
- Too much manual intervention needed.
- Web backend servers streamed data to user activity tracking system using HTTP requests:
- XML data collected and offloaded to an offline processing system.
- No real-time insight was available (data processed in hourly batches).
- Data from monitoring and activity tracking system could not be correlated easily:
- There exists difference between data models where pull-push method became problematic.
At first, ActiveMQ which is a popular traditional message broker was selected. Due to the middleware centric nature of this type of brokers while dispatching messages, it could not handle the data traffic that LinkedIn search engine encounters with. The flaws in that technology also caused broker instances grind to halt under heavy load.
After these bad experiences with ActiveMQ, they decided to implement a fit-for-purpose solution for LinkedIn. The technology needs to:
- Decouple data generators and users by using push-pull model
- Provide persistence for message data on messaging middleware with the ability to present data to multiple users
- Handle high data volume/throughput
- Scale up horizontally in case of need in proportion with data stream volume
What Apache Kafka aims to resolve
Kafka is a distributed system of servers and clients that communicate using a performant TCP-based binary network protocol6 in an asynchronous manner. It can be installed on bare-metal servers, virtual machines, and containers in on-premise corporate data centers as well as on public and private cloud based platforms. It simply collects and stores data in a distributed commit log which is an ordered sequence of events/facts with the time of happening. This is in fact the state of a system or domain under observation at a specific time or time frame.
With that model Kafka, as a centralized communication hub (nervous system), simplifies communication and message interchange between systems. Systems can send and receive data with no need to know each other. It also embraces the famous publish-subscribe integration pattern7 to publish (write) to and subscribe (read) to streams of events with continuously importing/exporting data from other systems.
Kafka has the ability to streams of events durably and reliably as long as it is needed (with the boundary of storage limits) on distributed commit log that it manages. With that event store it is also possible to process streams of events as they happened or historically. Kafka brings distributed, highly scalable, elastic, fault-tolerant, and secure deployment model.
Kafka as a messaging system
In its early days, Kafka appeared on the horizon as a messaging system. It is still a messaging system and also a streaming platform that stores data in distributed log files stored on persistent storage. These logs, in fact, are durable records of transactions. They provide a replay-able history and chain of events which can be used to re-build the state of a system at a certain time. Data is ordered and deterministically readable at partition (will be explained soon) level.
Kafka is architected to work in cluster mode that is scalable, distributed and highly available. If any of nodes (server or instance that hosts Kafka binaries) in a cluster fails, the load is handed off to other nodes to achieve resiliency and continuity. This also prevents data loss, protects against failures and brings performance benefit. As a messaging middleware, it sits between systems and abstracts communication and integration between them. It can support large number of ad-hoc consumers with no dependency on type or use-case of them. Kafka makes use of consumers that can process large batches of data in timely or windowed fashion with the help of Kafka client API.
Basic Concepts
Apache Kafka runs in a cluster consists of processing nodes called as brokers. It organizes messages into topics which are logs per use-case/concern. Producers are the clients that push messages to broker. Consumers are the clients that pull messages from brokers. Topics are divided into partitions that shard messages across cluster according to the message keys of events. The event ordering is guaranteed through partitions not through topics. An event consists of header, key, timestamp and value. Kafka does not care about message formats and structures, as all of the data stored on Kafka is in bytes for the sake of performance. It is up to the clients to serialize and de-serialize messages into more meaningful structure using supported formats such as Apache Avro, Google ProtoBuf and JSON.
Offsets
Kafka uses offsets as a unique identifier for messages they host on partitions. Offsets also denote the position of an ingested message in the partition. Consumers use offsets to define boundary of message (start-end indexes) stream that they need to consume. Kafka stores latest committed position by consumer to identify the next record that will be given out. Consumers can select automatic, periodic or manual committing. If a consumer app/process fails and restarts the consumer recovers the latest state by consuming events starting from latest committed offset on Kafka. Let’s say if a consumer has a offset position committed at 8th index, that means it consumed records with offset 0 through 7 and will start to receive record stream beginning at offset 8 at the next iteration. Kafka writes messages in order to partitions indexed uniquely and sequentially via offsets. The address of a message on Kafka contains:
- The topic that hosts the message
- The partition that hosts the message
- The unique offset assigned to the message by Kafka
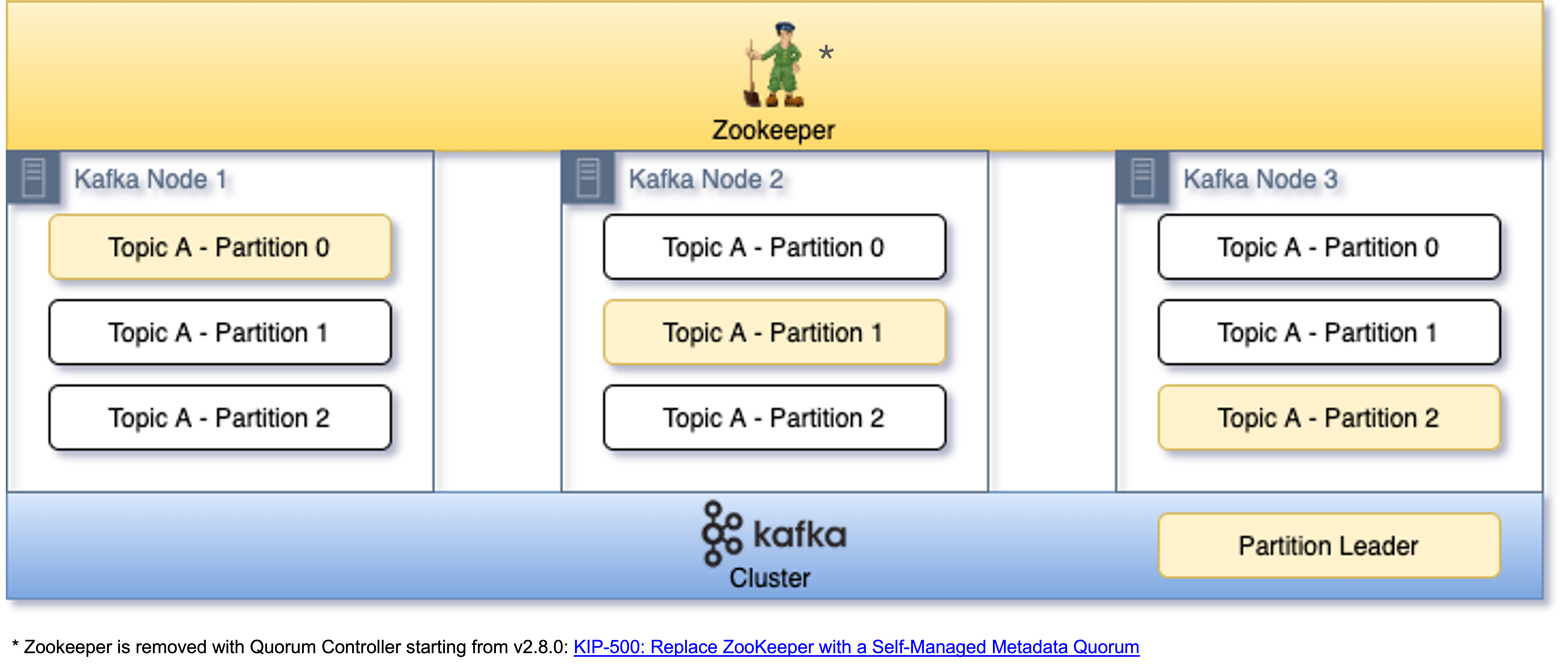
Zookeeper and its removal
As Kafka works in distributed fashion there needs to be a metadata manager (like etcd in a Kubernetes cluster) to store and manage the state of the clustered objects such as partitions, the role of replicas, etc. Another Apache project ZooKeeper was the choice to address this need. As the time passes, the evolution of Apache Kafka and the offerings brought by it raised questions on having and maintaining additional technology implementation like ZooKeeper. To avoid additional burden on management, communication and performance triggered the community to find a way to internalize the capabilities brought by ZooKeeper.
KIP-500: Replace ZooKeeper with a self-managed quorum is the improvement proposal that led to a new method of managing the metadata of cluster introduced in Kafka version 2.8.0: The Quorum Controller8. The set of controllers can be nodes on a existing Kafka cluster or on a different hardware stack in case of any need and they establish a quorum. These controllers use a brand new protocol called KRaft. This protocol is used to ensure that the metadata is consistently distributed and replicated across nodes using a new internal topic named @metadata. At its heart, KRaft inherits from well-known Raft algorithm which is designed to achieve consensus on distributed systems in a fault-tolerant and performant way. KRaft is also used to delegate role of leader in this quorum to a node which is the quorum controller.

At the time of writing, the implementation is not production ready yet and ZooKeeper is still the main dependency to shape a Kafka cluster in production grade systems.
Data Management
Kafka works on dumb broker-smart subscriber mode, which is why it does not care about the state of the consumer and just keeps data as an binary audit trail in distributed log files. Consumers need to know, store, build their state in case of any need. Consumers only communicate with partition leaders elected by Kafka for each topic.
To make the cluster fault-tolerant and highly-available, and to keep data intact the content of partitions on topics can be copied across brokers (both within corporate datacenters and across geographically dispersed availability zones). With that replication scheme the ingested data always has a copy on multiple brokers for the sake of resilience, backup and avoid outages in case of failures and maintenance operations. The best practice for setting replication factor in production deployment is an odd number, 3 at minimum, to achieve quorum in an election process.
Message Format
All messages on Kafka are stored/transmitted as raw bytes. It is required for performance in terms of high I/O throughput, less memory consumption and CPU cycles during data processing. Demo9 showed that a cloud hosted Kafka cluster handles 10GB/sec. Clients are responsible to serialize and de-serialize these byte streams to higher-level representations (e.g. String, Long, custom models) using protocol formats such as JSON, Avro, ProtoBuf. There is no message type or format checking on Kafka. Here is a list of external serializer/de-serializer (Serde) implementations that are needed for primitive types:
| Data Type | Serde |
|---|---|
byte[] |
Serdes.ByteArray(), Serdes.Bytes() |
ByteBuffer |
Serdes.ByteBuffer() |
Double |
Serdes.Double() |
Integer |
Serdes.Integer() |
Long |
Serdes.Long() |
String |
Serdes.String() |
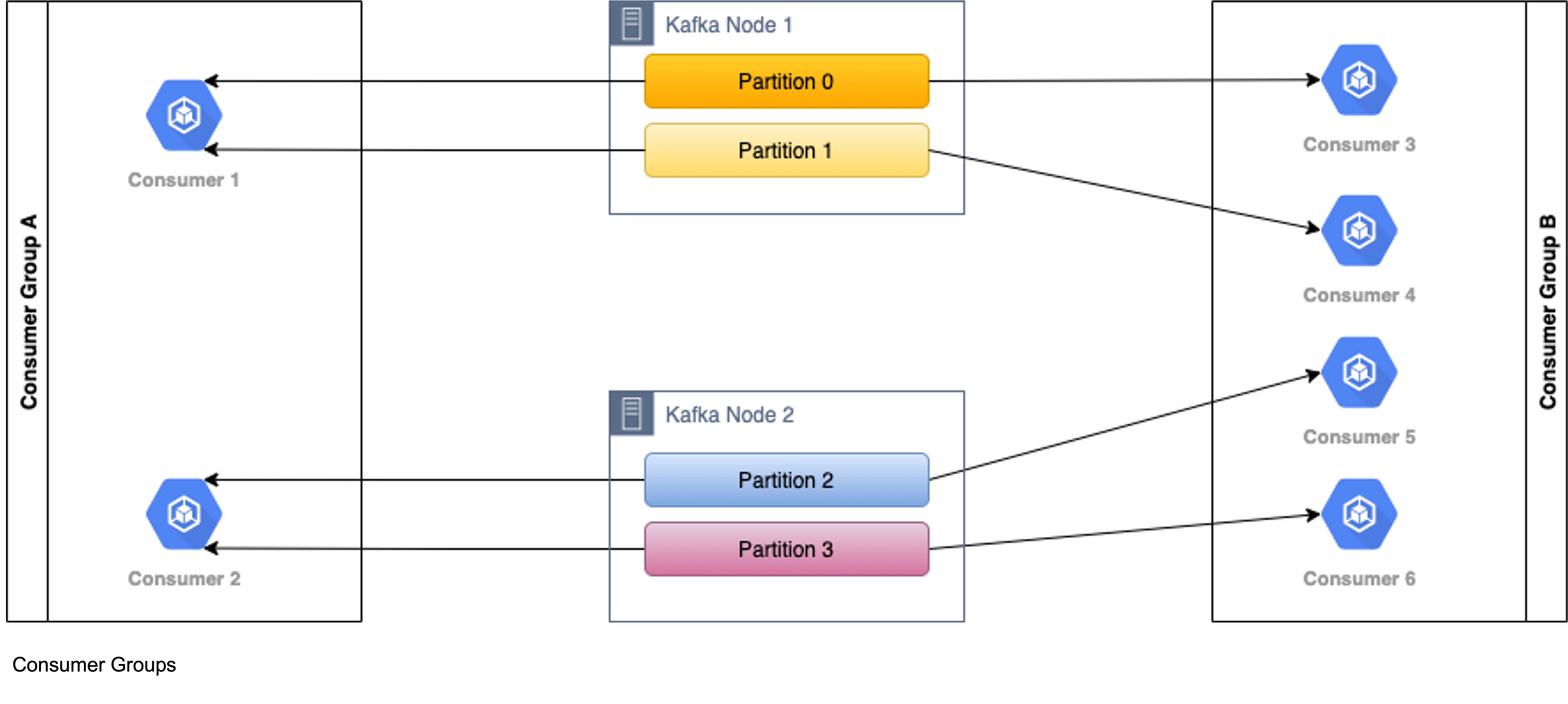
Consumer Groups
Consumer groups are set of consumers which cooperate to consume data in parallel. Partitions of all the topics are divided among the consumers in the group. Kafka automatically handles crashed consumers and re-assign previously assigned partitions to available consumers via re-balancing algorithm. Kafka elects a coordinator broker for each group to avoid anarchy (split brain problem) with managing members and partition assignments. The broker that hosts the leader of the partition number for a topic determined by the following formula is the group coordinator:
hash(group_id) % (partition # of internal offset topic)
This calculation balances the load of consumer group management across cluster equally, so that the number of groups can be scaled up via increasing number of brokers. The internal offsets topic __consumer_offsets, is used to store committed offsets. When a consumer starts up it finds the coordinator and requests joining that group. Each member must send heartbeats to the coordinator. In case of timeout coordinator kicks off the consumer from group and re-assigns its partitions to another member in group.
Using consumer groups enables read parallelization and high workload handling. To reap the benefits of it the number of consumers in a group should be equal to number of partitions in subscribed topic. A group with fewer members is also acceptable but it may overload some consumers as they can process messages from multiple partitions at a time. A group with more members than number of partitions is also acceptable, but some members will be idle during processing which is wasting of valuable resources. Different groups can be designated to consume data from same topic for different use cases. Consumers on a powerful platform/hardware stack can be grouped together to perform resource intensive streaming operations, like data science math. Another group with moderate consumers can be used for reporting that can be done within a flexible time frame like overnight batches.
Offset Management
Each consumer in a group determines initial position for reading from a partition. The position of initial reading is determined by consumer configuration auto.offset.reset with two options: earliest and latest which is default. Consumers commit offsets corresponding to the read messages. Default commit policy is auto which can be changed via enable.auto.commit consumer configuration. This ensures that any message is consumed “at least once”. The interval for auto commits is defined via auto.commit.interval.ms consumer configuration. To reduce duplicate reads after a crash or restart this interval should be reduced.
If a use case requires finer control on offset management this configuration should be set as false. The Kafka client API provides a commit()method that can be invoked within implementation in a controlled manner. If a message needs to be consumed “at most once” this API call can be used with synchronous mode (KafkaConsumer.commitSync()) where the consumer retries/blocked until commit succeeds.
If asynchronous mode via KafkaConsumer.commitAsync() is used consumer does not retry on failures, just fires and forgets the commit call. This is more performant then synchronous commits but more unsafe as there may exist a ordering problem that may lead to duplicate reads.
If a consumer crashes or shuts down its partitions are assigned to another member in the group. If it crashes after committing the offset newly assigned consumer starts reading from last committed offset of each partition. If it crashes before committing newly assigned consumer starts reading based on auto.offset.reset policy for that consumer. After consumer restart or re-balance the position of all partitions owned by crashed consumer will be reset to last committed offset. The last committed position may be as old as the auto-commit interval itself. Any messages arrived since the last commit will have to be read again.
Replication and Partitions
Kafka evenly distributes messages across partitions according to following formula:
murmur_hash(message_key) % (total # of partitions)
The message key hashed with murmur hash function and the reminder of division of it by total number of partitions for topic gives the partition number to write. A sample Python code demonstrates this as follow:
>>> import murmurhash
>>> murmurhash.hash('id_1234')
-286100597
>>> murmurhash.hash('id_1234') % 3
1
>>> murmurhash.hash('id_1234') % 3
1
>>> murmurhash.hash('id_4321') % 3
0
>>> murmurhash.hash('id_4320') % 3
2
>>> murmurhash.hash('id_4319') % 3
0
If message key is set as nullKafka randomly selects a partition and uses it for forthcoming ones for 10 minutes which is also configurable. As sated before, order is only guaranteed within partition, not across all partitions of a topic.
Schema Registry
Each message on a topic comprises of key and value. It can be serialized and deserialized as Avro, JSON and ProtoBuf data formats. ProtoBuf and Avro have compact byte representations and they bring network bandwidth and storage benefits. A schema is structure of data format for both message key and value. As Kafka does not enforce any format checking additional technologies or methods needed to apply such a validation scheme for messages. That is why Confluent designed a solution called Schema Registry that exposes RESTful interfaces to store and retrieve schemas and supports Avro, JSON, ProtoBuf formats. A sample Avro schema is as follows and avro-maven-plugin can be used to generate serializable model/event classes from that schema:
[
{
"type": "enum",
"name": "TaskState",
"namespace": "com.corp.concepts.taskmanager.models",
"symbols": [
"ASSIGNED",
"STARTED",
"COMPLETED",
"PENDING"
]
},
{
"type": "record",
"name": "Task",
"namespace": "com.corp.concepts.taskmanager.models",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "userid",
"type": "string"
},
{
"name": "duedate",
"type": "string"
},
{
"name": "title",
"type": "string"
},
{
"name": "details",
"type": "string"
},
{
"name": "status",
"type": "TaskState"
}
]
}
]
It can also tracks versions for schemas based on subject names that Schema Registry groups on. There exists a naming strategy for subject names. There are three options:
- TopicNameStrategy: Subject name based on topic name. It is the default setting.
- RecordNameStrategy: Subject name based on event record models on same topics. Used to group events with different data structures on same topic.
- TopicRecordNameStrategy: Combined version of strategies above. Used to group logically related events with different structures under a subject.
If TopicNameStrategy is used all messages in the same topic should conform to the same schema (one schema per topic). Otherwise, a new record type can break compatibility checks on the topic. This strategy works well where all messages can be grouped by topic (e.g. logging events). Other types of naming strategies suit well where a topic can have records with multiple schemas. One can register multiple versions of a schema. Schema Registry checks whether it is forward or backward compatible. Different producers and consumers can co-exist with different versions of same schema in a compatible way. To integrate with Schema Registry serializer and de-serializer (SerDe) implementations are needed. Java, .NET, Python and Ruby are the supported programming languages for SerDe libraries.
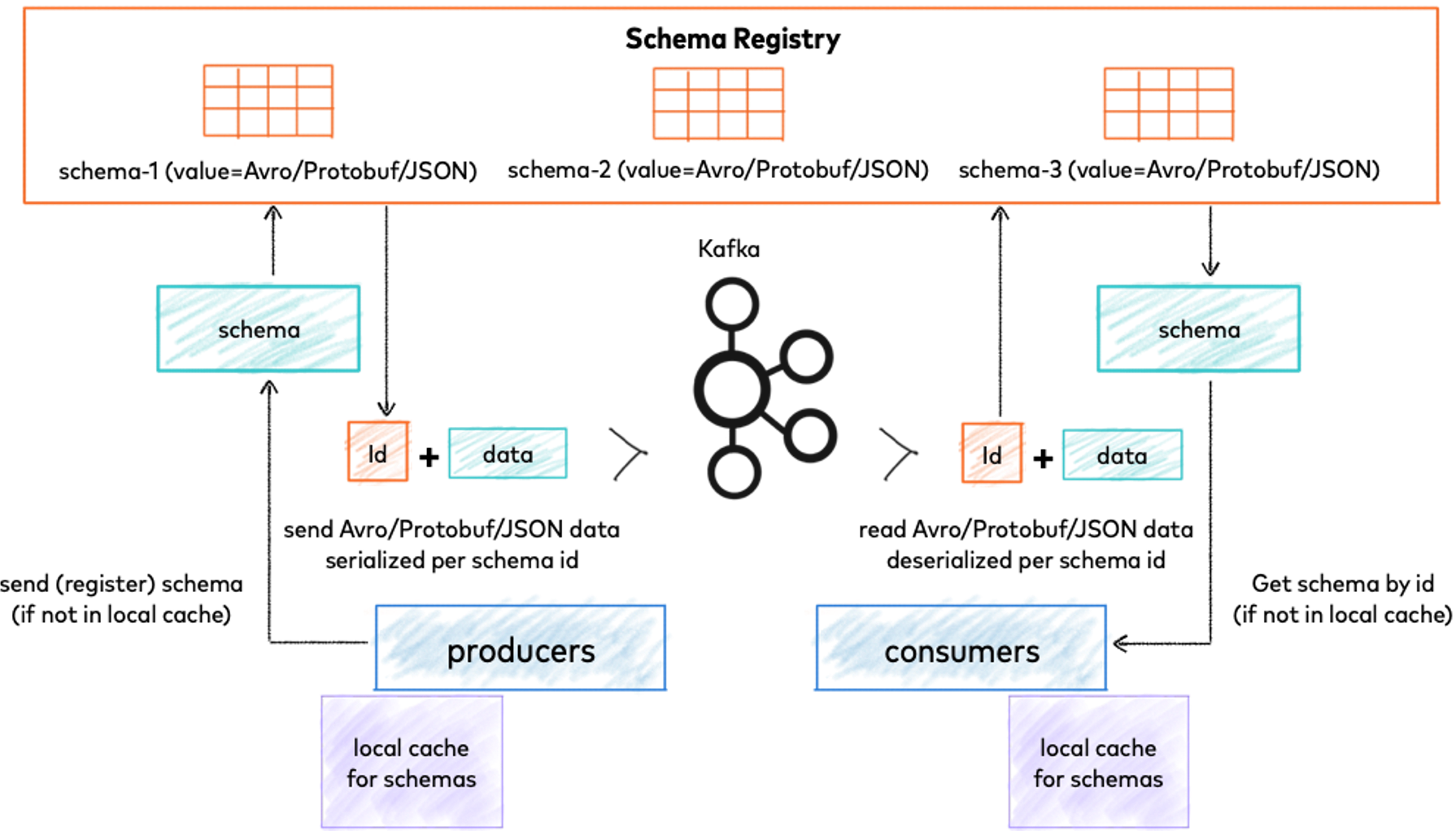
Schema Registry works as an external compute node separate from Kafka brokers. It uses Kafka as underlying storage layer that is distributed and durable. Producers can concurrently query Schema Registry to submit and retrieve schemas of event data models. Each schema has a unique ID assigned globally. It is monotonically increasing and unique and it may not be consecutively incremented. It supports working in distributed mode with single-master architecture. Zookeeper coordinates primary node selection in that architecture.
It is also possible to use embedded schema included in events which can be used by clients to define and validate event models. This method is easy to use, brings no additional management and point of failure burdens. However, the event payload size is bigger as additional schema data is included in event payload. When Using Schema Registry the event payload is smaller as schema is stored on Schema Registry. Schema versioning and validation also available on Schema Registry. Schema Registry client libraries have the ability to cache schemas on application that minimize lookup of schemas from remote registry instance. The Achilles heel of Schema Registry is that as a external dependency it stands as a single point of failure. Schema Registry supports working in cluster mode that can be used as a mitigation.
REST Proxy
REST Proxy is a utility developed by Confluent that enables integration with Kafka brokers using HTTP/REST without need of native Kafka protocol or client implementations. It is possible to produce and consume events, monitor Kafka cluster and execute administrative commands using REST Proxy. Some use cases that fit REST Proxy usage are:
- Directly streaming data to;
- A client app (web, mobile) that can call REST APIs
- An app that is not implemented with supported languages (C, Java, .NET, Go, Python) for Kafka clients
- Using streaming data in a data engineering platform that does not have support of Kafka but REST
- Quickly performing administrative actions in an environment that does not have terminal application
- Ability to authenticate requests and utilize multi-tenant security features of Kafka
Following is an example to get cluster info using REST Proxy:
curl --location --request GET 'http://web.poc.local:8082/v3/clusters/'
{
"kind": "KafkaClusterList",
"metadata": {
"self": "http://web.poc.local:8082/v3/clusters",
"next": null
},
"data": [
{
"kind": "KafkaCluster",
"metadata": {
"self": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw",
"resource_name": "crn:///kafka=ntcqkZ0dR2SmRmMV7Ayjgw"
},
"cluster_id": "ntcqkZ0dR2SmRmMV7Ayjgw",
"controller": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/brokers/2"
},
"acls": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/acls"
},
"brokers": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/brokers"
},
"broker_configs": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/broker-configs"
},
"consumer_groups": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/consumer-groups"
},
"topics": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics"
},
"partition_reassignments": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics/-/partitions/-/reassignment"
}
}
]
}
Following is an example to get topic info using REST Proxy:
curl --location --request GET 'http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics'
{
"kind": "KafkaTopicList",
"metadata": {
"self": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics",
"next": null
},
"data": [
{
"kind": "KafkaTopic",
"metadata": {
"self": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics/tasks",
"resource_name": "crn:///kafka=ntcqkZ0dR2SmRmMV7Ayjgw/topic=tasks"
},
"cluster_id": "ntcqkZ0dR2SmRmMV7Ayjgw",
"topic_name": "tasks",
"is_internal": false,
"replication_factor": 3,
"partitions": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics/tasks/partitions"
},
"configs": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics/tasks/configs"
},
"partition_reassignments": {
"related": "http://web.poc.local:8082/v3/clusters/ntcqkZ0dR2SmRmMV7Ayjgw/topics/tasks/partitions/-/reassignment"
}
},
…
]
}
Following is an example to fire an event using NodeJS:
What is next?
This is the first part of Apache Kafka article series. The next one is about cutting-edge Kafka Streams technology that enables to implement Microservices Architecture (MSA) compliant stream processing/event streaming applications using Apache Kafka as a data backbone with all of the scalability and availability features of Kafka cluster.
References
- Kafka: The Definitive Guide, Neha Narkhede, Gwen Shapira, Todd Palino
- Designing Event-Driven Systems, Ben Stopford
- Apache Kafka Documentation, https://kafka.apache.org/documentation
- Confluent Kafka Documentation, https://docs.confluent.io/home/overview.html
-
https://kafka.apache.org/intro#intro_platform ↩
-
https://www.foreignaffairs.com/articles/united-states/2021-04-16/data-power-new-rules-digital-age ↩
-
https://www.quora.com/What-is-the-relation-between-Kafka-the-writer-and-Apache-Kafka-the-distributed-messaging-system/answer/Jay-Kreps ↩
-
https://www.forbes.com/sites/stevenli1/2020/05/11/confluent-jay-kreps-kafka-4-billion-2020 ↩
-
https://stackshare.io/kafka ↩
-
https://kafka.apache.org/protocol#protocol_network ↩
-
https://www.enterpriseintegrationpatterns.com/patterns/messaging/PublishSubscribeChannel.html ↩
-
https://www.confluent.io/blog/kafka-2-8-0-features-and-improvements-with-early-access-to-kip-500/ ↩
-
https://www.confluent.io/blog/scaling-kafka-to-10-gb-per-second-in-confluent-cloud/ ↩